Aws Hadoop

Q Tbn And9gcqrmbfoho40ikqzlf6k6imp63uvsusdqd0w0n4gg1nldqrbiede Usqp Cau

What Is Hadoop

Big Data On Cloud Hadoop And Spark On Emr Kaizen

Project Management Technology Fusion Apache Hadoop Spark Kafka Versus Aws Emr Spark Kinesis Stream
Q Tbn And9gcqdtbp2ce7csqlaxbeui4xpeys0mkqum58qvtrmibdgdpajoj Usqp Cau
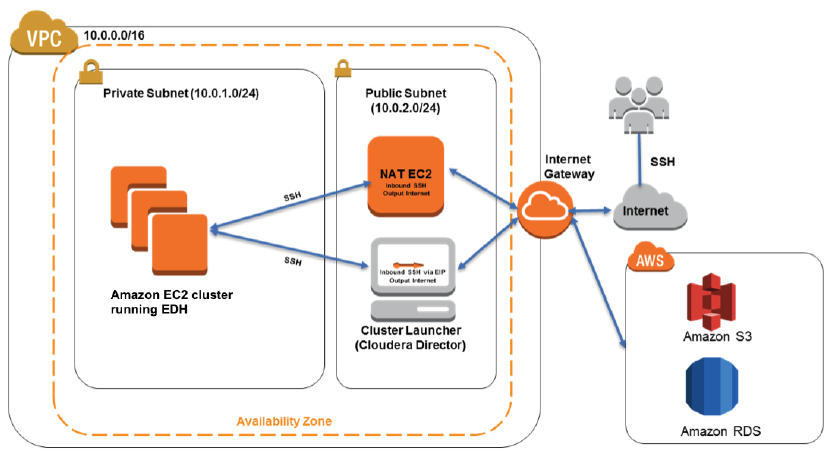
New Aws Quick Start Cloudera Enterprise Data Hub Aws News Blog
Hadoop is suitable for Massive Offline batch processing, by nature cannot be and should not be used for online analytic Unlikely, Amazon Redshift is built for Online analytical purposes * Massively parallel processing * Columnar data storage.

Aws hadoop. There are a lot of topics to cover, and it may be best to start with the keystrokes needed to standup a cluster of four AWS instances running Hadoop and Spark using Pegasus Clone the Pegasus repository and set the necessary environment variables detailed in the ‘ Manual ’ installation of Pegasus Readme. ️ Setup AWS instance We are going to create an EC2 instance using the latest Ubuntu Server as OS After logging on AWS, go to AWS Console, choose the EC2 service On the EC2 Dashboard, click on Launch Instance. The following tables list the version of Hadoop included in each release version of Amazon EMR, along with the components installed with the application For component versions in each release, see the Component Version section for your release in Amazon EMR 5x Release Versions or Amazon EMR 4x Release Versions Did this page help you?.
Hadoop, at it’s version # 1 was a combination of Map/Reduce compute framework and HDFS distributed file system We are now well into version 2 of hadoop and the reality is Map/Reduce is legacy Apache Spark, HBase, Flink and others are. Hadoop is suitable for Massive Offline batch processing, by nature cannot be and should not be used for online analytic Unlikely, Amazon Redshift is built for Online analytical purposes * Massively parallel processing * Columnar data storage. Browse files in S3 and Hdfs — “hadoop fs cat” can be used to browse data in S3 and EMR Hdfs as below Here head along with “” character is used to limit the number of rows Browse S3 data.
As opposed to AWS EMR, which is a cloud platform, Hadoop is a data storage and analytics program developed by Apache You can think of it this way if AWS EMR is an entire car, then Hadoop is akin to the engine. AWS ProServe Hadoop Cloud Migration for Property and Casualty Insurance Leader Our client is a leader in property and casualty insurance, group benefits and mutual funds With more than 0 years of expertise, the company is widely recognized for its service excellence, sustainability practices, trust and integrity. There are a lot of topics to cover, and it may be best to start with the keystrokes needed to standup a cluster of four AWS instances running Hadoop and Spark using Pegasus Clone the Pegasus repository and set the necessary environment variables detailed in the ‘ Manual ’ installation of Pegasus Readme.
Apache Hadoop is an open source framework that is used to efficiently store and process large datasets ranging in size from gigabytes to petabytes of data Instead of using one large computer to store and process the data, Hadoop allows clustering multiple computers to analyze massive datasets in parallel more quickly. Try our Hadoop cluster;. Try our Hadoop cluster;.
Apache Hadoop’s hadoopaws module provides support for AWS integration applications to easily use this support To include the S3A client in Apache Hadoop’s default classpath Make sure that HADOOP_OPTIONAL_TOOLS in hadoopenvsh includes hadoopaws in its list of optional modules to add in the classpath. The hadoopaws module provides support for AWS integration The generated JAR file, hadoopawsjar also declares a transitive dependency on all external artifacts which are needed for this support —enabling downstream applications to easily use this support. AWS Hadoop Training Looking for online training session on daily basis, Expecting more real time oriented training rather then having theoretical classes Looking forward to discuss more job related day to day real time issues and troubleshooting.
Apache Hadoop is an opensource Java software framework that supports massive data processing across a cluster of instances It can run on a single instance or thousands of instances. Hadoop and HDFS commoditized big data storage by making it cheap to store and distribute a large amount of data However, in a cloud native architecture, the benefit of HDFS is minimal and not worth the operational complexity That is why many organizations do not operate HDFS in the cloud, but instead use S3 as the storage backend. AWS is here to help you migrate your big data and applications Our Apache Hadoop and Apache Spark to Amazon EMR Migration Acceleration Program provides two ways to help you get there quickly and with confidence.
Try our Hadoop cluster;. Hive is an opensource, data warehouse, and analytic package that runs on top of a Hadoop cluster Hive scripts use an SQLlike language called Hive QL (query language) that abstracts programming models and supports typical data warehouse interactions. This tutorial illustrates how to connect to the Amazon AWS system and run a Hadoop/MapReduce program on this service The first part of the tutorial deals with the wordcount program already covered in the Hadoop Tutorial 1The second part deals with the same wordcount program, but this time we'll provide our own version.
This is a step by step guide to install a Hadoop cluster on Amazon EC2 I have my AWS EC2 instance ecapsoutheast1computeamazonawscom ready on which I will install and configure Hadoop, java 17 is already installed In case java is not installed on you AWS EC2 instance, use below commands. From above, EMR default HDFS folder is /user/hadoop/ as the test folder freddiehdfs was created in location /user/hadoop/ Default hive folder is /user/hive/warehouse/ All the tables created in. Apache Hadoop Amazon Web Services Support This module contains code to support integration with Amazon Web Services It also declares the dependencies needed to work with AWS services Central (43).
Setup & config instances on AWS;. Hadoop on AWS Cluster Starting up Cluster Finished Startup Master node public DNS Upload your jar file to run a job using steps, you can run a job by doing ssh to the master node as well (shown later) Location of jar file on s3 EMR started the master and worker nodes as EC2 instances. HadoopAWS module Integration with Amazon Web Services The hadoopaws module provides support for AWS integration The generated JAR file, hadoopawsjar also declares a transitive dependency on all external artifacts which are needed for this support —enabling downstream applications to easily use this support Features The “classic” s3 filesystem for storing objects in Amazon S3.
AWS ProServe Hadoop Cloud Migration for Property and Casualty Insurance Leader Our client is a leader in property and casualty insurance, group benefits and mutual funds With more than 0 years of expertise, the company is widely recognized for its service excellence, sustainability practices, trust and integrity. Supervising Hadoop jobs using scheduler. It will pull in a compatible awssdk JAR The hadoopaws JAR does not declare any dependencies other than that dependencies unique to it, the AWS SDK.
Let us discuss some of the major differences AWS EC2 users can configure their own VMS or preconfigured images whereas Azure users need to choose the virtual hard disk to create a VM which is preconfigured by the third party and need to specify the number of cores and memory required. Amazon Web Services (AWS) is a Public Cloud platform from a proprietary company, Amazon Hadoop is an opensource Javabased technology and Big Data processing, storing stack from Apache Software Foundation. Lastly, because AWS EMR is a software as a service (SaaS) and it’s backed by Amazon, it allows professionals to access support quickly and efficiently Hadoop 101 As opposed to AWS EMR, which is a cloud platform, Hadoop is a data storage and analytics program developed by Apache.
Hadoopaws JAR awsjavasdkbundle JAR The versions of hadoopcommon and hadoopaws must be identical To import the libraries into a Maven build, add hadoopaws JAR to the build dependencies;. Lack of agility, excessive costs, and administrative overhead are convincing onpremises Spark and Hadoop customers to migrate to cloud native services on AWS As you’re migrating these applications to the cloud, Unravel helps ensure you won’t be flying blind Join AWS and Unravel as we discuss. This is a step by step guide to install a Hadoop cluster on Amazon EC2 I have my AWS EC2 instance ecapsoutheast1computeamazonawscom ready on which I will install and configure Hadoop, java 17 is already installed In case java is not installed on you AWS EC2 instance, use below commands.
This tutorial illustrates how to connect to the Amazon AWS system and run a Hadoop/MapReduce program on this service The first part of the tutorial deals with the wordcount program already covered in the Hadoop Tutorial 1The second part deals with the same wordcount program, but this time we'll provide our own version. It will pull in a compatible awssdk JAR The hadoopaws JAR does not declare any dependencies other than that dependencies unique to it, the AWS SDK. It will pull in a compatible awssdk JAR The hadoopaws JAR does not declare any dependencies other than that dependencies unique to it, the AWS SDK.
Hadoopaws JAR awsjavasdkbundle JAR The versions of hadoopcommon and hadoopaws must be identical To import the libraries into a Maven build, add hadoopaws JAR to the build dependencies;. ️ Setup AWS instance We are going to create an EC2 instance using the latest Ubuntu Server as OS After logging on AWS, go to AWS Console, choose the EC2 service On the EC2 Dashboard, click on Launch Instance. The following tables list the version of Hadoop included in each release version of Amazon EMR, along with the components installed with the application For component versions in each release, see the Component Version section for your release in Amazon EMR 5x Release Versions or Amazon EMR 4x Release Versions Did this page help you?.
Amazon Web Services (AWS) is a Public Cloud platform from a proprietary company, Amazon Hadoop is an opensource Javabased technology and Big Data processing, storing stack from Apache Software Foundation. Hadoop is suitable for Massive Offline batch processing, by nature cannot be and should not be used for online analytic Unlikely, Amazon Redshift is built for Online analytical purposes * Massively parallel processing * Columnar data storage. This is a step by step guide to install a Hadoop cluster on Amazon EC2 I have my AWS EC2 instance ecapsoutheast1computeamazonawscom ready on which I will install and configure Hadoop, java 17 is already installed In case java is not installed on you AWS EC2 instance, use below commands.
Setup & config a Hadoop cluster on these instances;. AWS provides some managed services to build a Hadoop cluster, but there aren't too many options for the EC2 instance type you can choose (for example, m2micro instance is not an option). HadoopAWS module Integration with Amazon Web Services The hadoopaws module provides support for AWS integration The generated JAR file, hadoopawsjar also declares a transitive dependency on all external artifacts which are needed for this support —enabling downstream applications to easily use this support Features The “classic” s3 filesystem for storing objects in Amazon S3.
Apache Hadoop Amazon Web Services Support This module contains code to support integration with Amazon Web Services It also declares the dependencies needed to work with AWS services License Apache s amazon aws hadoop apache Used By 170 artifacts Central (43) Cloudera (11). Key Differences Between AWS and Azure Both are popular choices in the market;. Apache Hadoop’s hadoopaws module provides support for AWS integration applications to easily use this support To include the S3A client in Apache Hadoop’s default classpath Make sure that HADOOP_OPTIONAL_TOOLS in hadoopenvsh includes hadoopaws in its list of optional modules to add in the classpath.
Excellent knowledge of Linux as Hadoop runs on Linux Implementation and support experience with the Enterprise Hadoop environment Responsibilities Performance tuning in environment likes BigData/Cloud (AWS) and RDBMS (Oracle, SQL Server etc,)Handling Hadoop Log Files;. FAQs Amazon EMR is a managed service that makes it fast, easy, and costeffective to run Apache Hadoop and Spark to process vast amounts of data Amazon EMR also supports powerful and proven Hadoop tools such as Presto, Hive, Pig, HBase, and more. Setup & config a Hadoop cluster on these instances;.
Hadoop, at it’s version # 1 was a combination of Map/Reduce compute framework and HDFS distributed file system We are now well into version 2 of hadoop and the reality is Map/Reduce is legacy Apache Spark, HBase, Flink and others are. Apache™ Hadoop® is an open source software project that can be used to efficiently process large datasets Instead of using one large computer to process and store the data, Hadoop allows clustering commodity hardware together to analyze massive data sets in parallel. Hadoop cluster on AWS setup, In this tutorial one can easily know the information about Apache Hadoop Installation and Cluster setup on AWS which are available and are used by most of the Hadoop developers.
Setup & config instances on AWS;. A key part of the Workshop is discussing your current onpremises Apache Hadoop/Spark architecture, your workloads, and your desired future architecture Complete the form and one of our technical experts will contact you to confirm the best date and time for your team to attend the online workshop. It will pull in a compatible awssdk JAR The hadoopaws JAR does not declare any dependencies other than that dependencies unique to it, the AWS SDK.
Lets talk about how to setup an Apache Hadoop cluster on AWS In a previous article, we discussed setting up a Hadoop processing pipeline on a single node (laptop) That involved running all the components of Hadoop on a single machine In the setup we discuss here, we setup a multinode cluster to run processing jobs. Setup & config a Hadoop cluster on these instances;. Hadoopaws JAR awsjavasdkbundle JAR The versions of hadoopcommon and hadoopaws must be identical To import the libraries into a Maven build, add hadoopaws JAR to the build dependencies;.
AWS Cloud Infrastructure Architect/Big Data, Cloudera Hadoop/is required to lead the architecture of cloud solutions based on Amazon technology stack on a large scale Big Data programme You will be a Solution Architect by trade with following experience. AWS Security Group (without security 😇) Finally, click on Review and Launch We need to create a key pair in order to connect to our instance securely, here through SSH Select Create a new key pair from the first dropbox, give a name to the key pair (eg hadoopec2cluster) and download it. AWS Redshift is a cloud data warehouse that uses an MPP architecture (very similar to Hadoop’s distributed file system we recommend reading our guide) and columnar storage, making analytical queries very fast Moreover, it is SQL based, which makes it easy to adopt by data analysts.
AWS is here to help you migrate your big data and applications Our Apache Hadoop and Apache Spark to Amazon EMR Migration Acceleration Program provides two ways to help you get there quickly and with confidence. You'll need to include what may at first seem to be an out of date AWS SDK library (built in 14 as version 174) for versions of Hadoop as late as 271 (stable) awsjavasdk 174 As far as I can tell using this along with the specific AWS SDK JARs for 1108 hasn't broken anything You'll also need the hadoopaws 271 JAR on the classpath. Hadoopaws JAR awsjavasdkbundle JAR The versions of hadoopcommon and hadoopaws must be identical To import the libraries into a Maven build, add hadoopaws JAR to the build dependencies;.
This article is the 2nd part of a serie of several posts where I describe how to build a 3node Hadoop cluster on AWS • Part 1 Setup EC2 instances with AWS CloudFormation Following our previous. Apache Hadoop Amazon Web Services Support This module contains code to support integration with Amazon Web Services It also declares the dependencies needed to work with AWS services Central (43). ️ Setup AWS instance We are going to create an EC2 instance using the latest Ubuntu Server as OS After logging on AWS, go to AWS Console, choose the EC2 service On the EC2 Dashboard, click on Launch Instance.
As mentioned we are setting up 4 node hadoop cluster, so please enter 4 as number of instances please check amazon ec2 freetier requirements, you may setup 3 node cluster with < 30gb storage. Setup & config instances on AWS;. AWS Cloud Infrastructure Architect/Big Data, Cloudera Hadoop/is required to lead the architecture of cloud solutions based on Amazon technology stack on a large scale Big Data programme You will be a Solution Architect by trade with following experience.
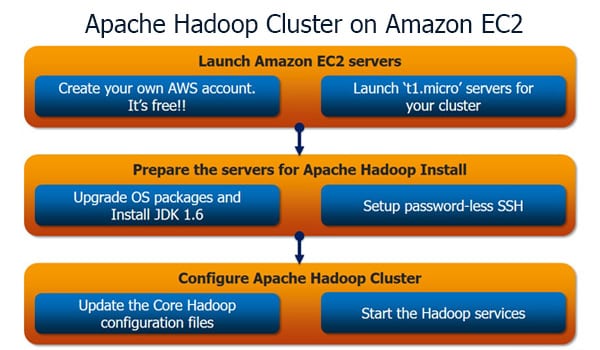
How To Install Apache Hadoop Cluster On Amazon Ec2 Tutorial Edureka

Launching And Running An Amazon Emr Cluster Inside A Vpc Aws Big Data Blog
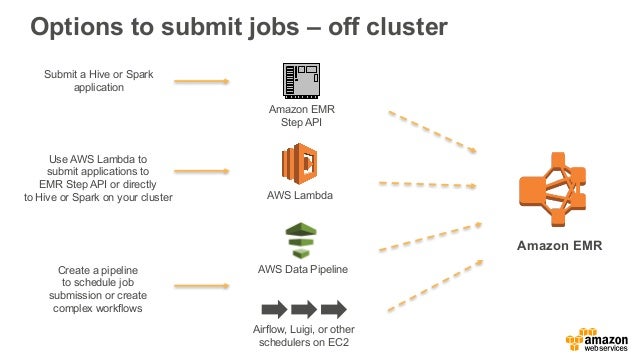
Apache Hadoop And Spark On Aws Getting Started With Amazon Emr Pop
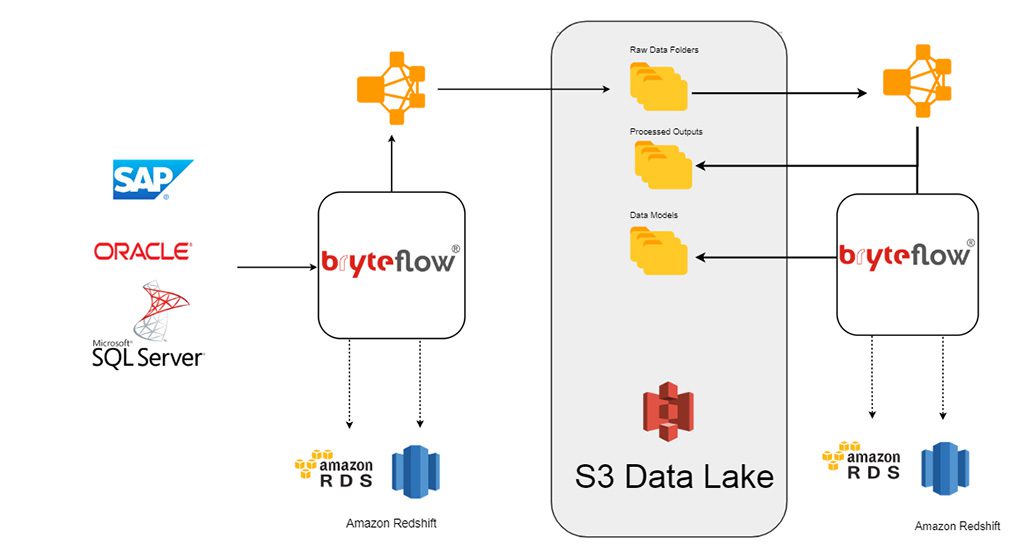
Why Hadoop Data Lakes Are Not The Modern Architect S Choice Bryteflow

Big Data And Cloud Tips

How To Setup An Apache Hadoop Cluster On Aws Ec2 Novixys Software Dev Blog

Building For The Internet Of Things With Hadoop

Aws Emr Spark On Hadoop Scala Anshuman Guha

Installing An Aws Emr Cluster Tutorial Big Data Demystified

How To Create Hadoop Cluster With Amazon Emr Edureka
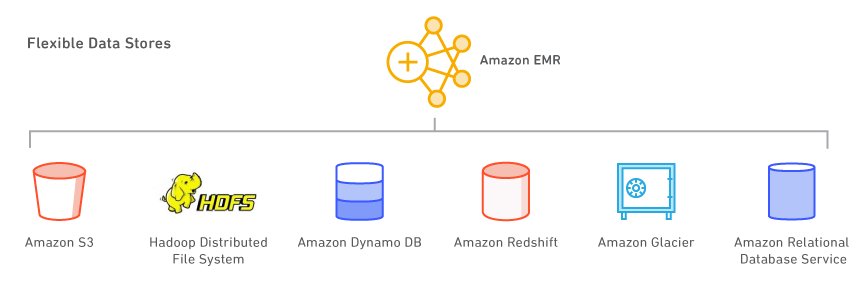
Amazon Emr Features Big Data Platform Amazon Web Services

Using Aws Systems Manager Run Command To Submit Spark Hadoop Jobs On Amazon Emr Aws Management Governance Blog

Amazon Emr Vs Hadoop What Are The Differences

How To Get Hadoop And Spark Up And Running On Aws By Hoa Nguyen Insight

Hadoop Aws Marketplace
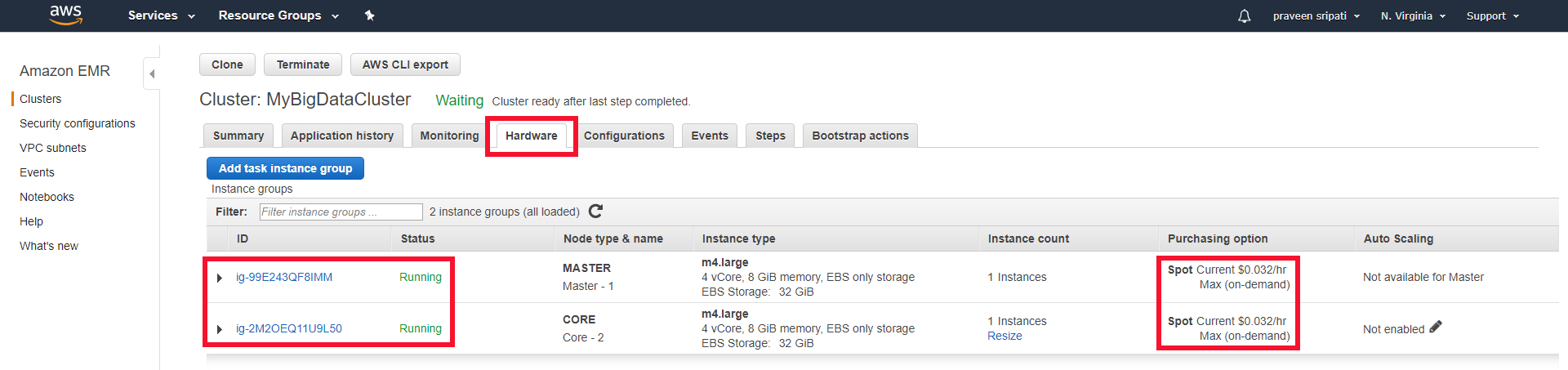
How To Create Hadoop Cluster With Amazon Emr Edureka

Apache Hadoop To Aws Emr Migration All You Need To Know Blazeclan

Cost Analysis Of Building Hadoop Clusters Using Cloud Technologies Qubole

Hadoop Migration Guided Workshop With Aws Databricks

How To Run A Hive Script On An Aws Hadoop Cluster Virtualization Review

Big Data On Amazon
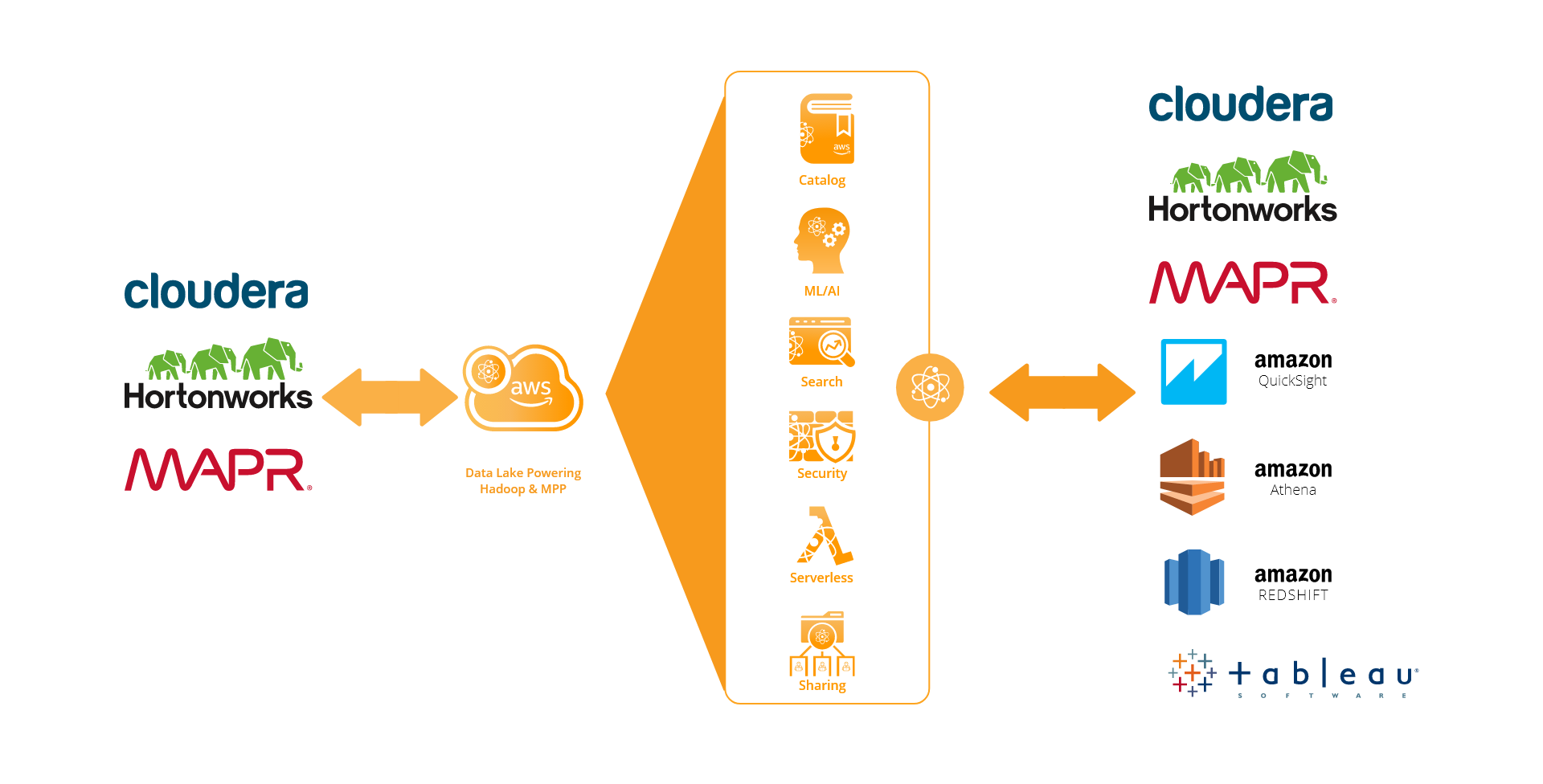
Hadoop Migration Cloudwick The Cloud Data Lake And Analytics Company

Launching Your First Big Data Project On Aws Youtube
Q Tbn And9gcsymx3y9uuf6x4gvkgeikshp2tohcofher0e Fobymm5oqdp6p5 Usqp Cau

Aws Proserve Hadoop Cloud Migration For Property And Casualty Insurance Leader Softserve
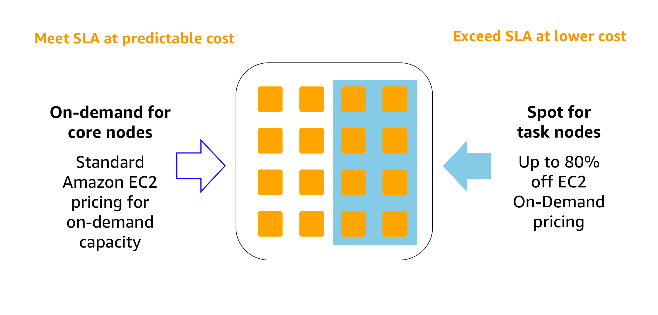
Amazon Emr Aws Big Data Blog

Netflix Open Sources Its Hadoop Manager For Aws Open Source Netflix Data Analysis Tools

Big Data Analytics Powered By Hadoop Faction Inc
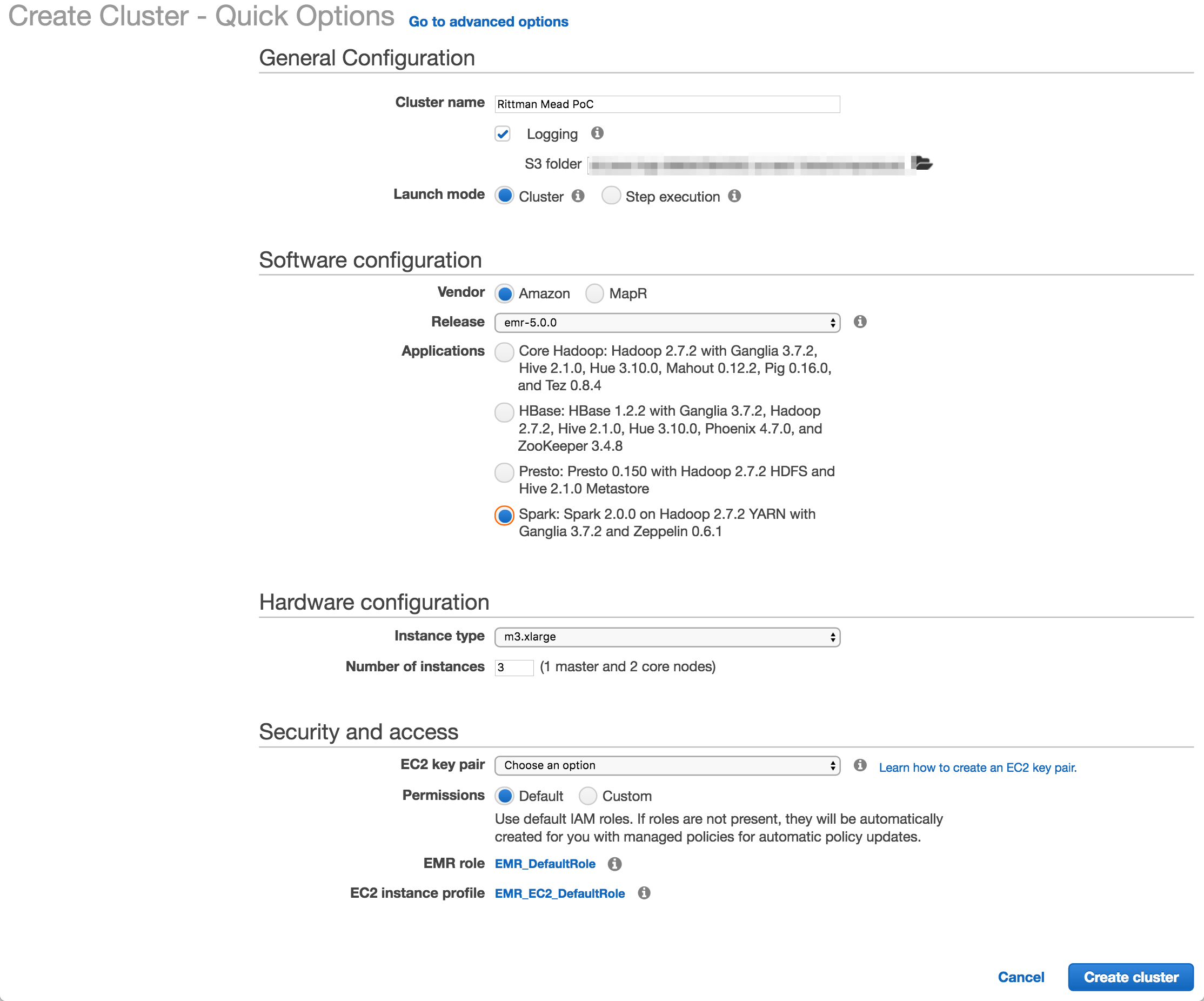
Etl Offload With Spark And Amazon Emr Part 3 Running Pyspark On Emr

How To Setup An Apache Hadoop Cluster On Aws Ec2 Novixys Software Dev Blog
Hadoop On Aws
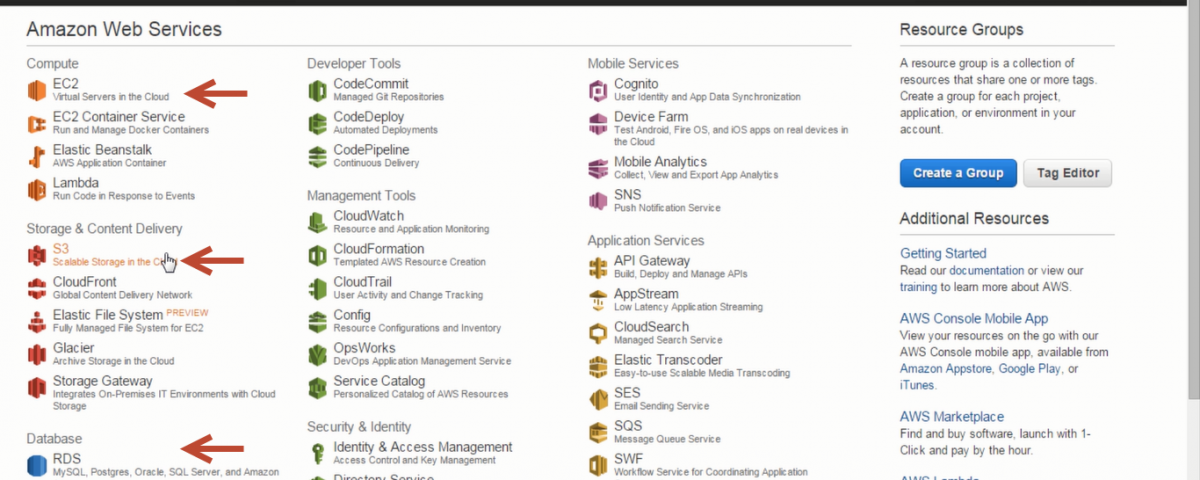
Creating Ec2 Instances In Aws To Launch A Hadoop Cluster Hadoop In Real World
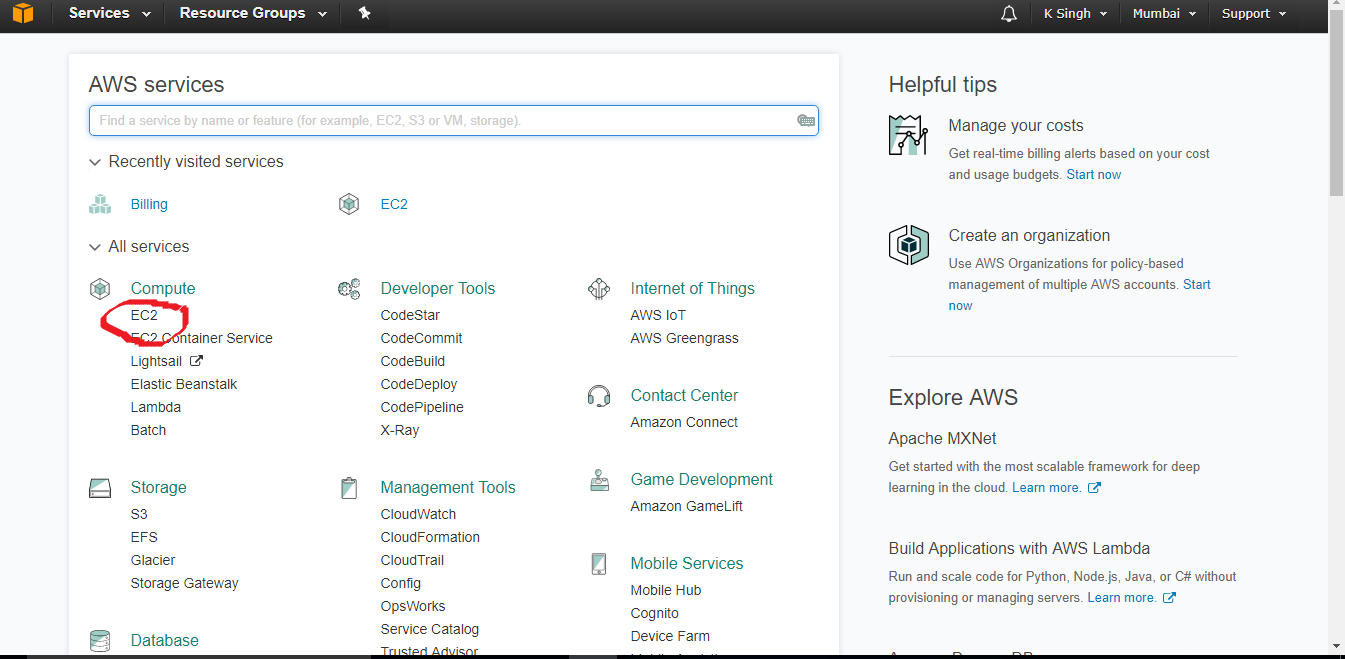
My Bigdata Blog Creating Hadoop Cluster On Aws
Advantages And Complexities Of Integrating Hadoop With Object Stores Cloud Computing News
Hadoop Workloads On Aws Azure Gce And Oci Download Scientific Diagram
Q Tbn And9gcsyjxdjvgbdh97xfv1ibyv5ns6mue4vuslxor9txjjzmafwtwun Usqp Cau

Using Partition Placement Groups For Large Distributed And Replicated Workloads In Amazon Ec2 Aws Compute Blog
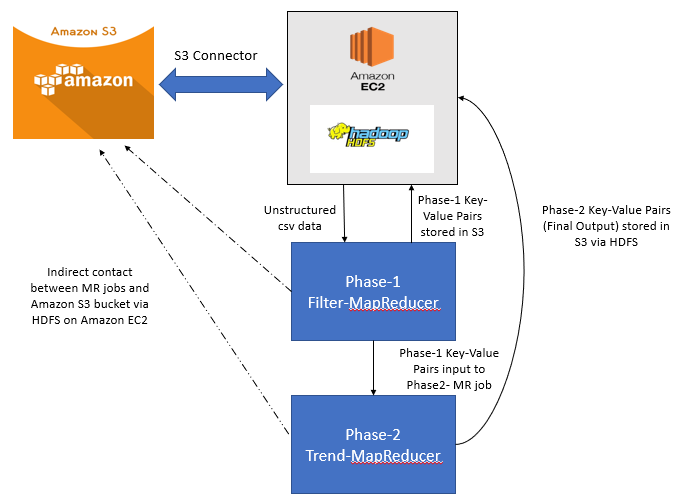
Map Reduce With Amazon Ec2 And S3 By Sanchit Gawde Medium

Hdfs Vs S3 Aws S3 Vs Hadoop Hdfs Youtube

Amazon Web Services Releases Version 5 0 0 Of Elastic Mapreduce Which Updates Eight Hadoop Projects Geekwire

Hadoop Tutorial 3 3 How Much For 1 Month Of Aws Mapreduce Dftwiki
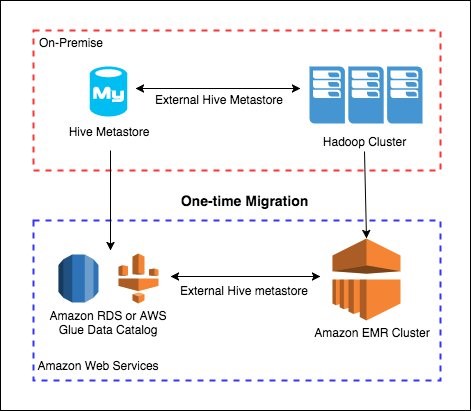
Migrate And Deploy Your Apache Hive Metastore On Amazon Emr Aws Big Data Blog

Aws Blog Accelerating Apache And Hadoop Migrations With Cazena S Saas Data Lake On Aws Cazena Cazena

Creating A Kerberized Emr Cluster For Use With Ae 5 Anaconda Platform 5 2 0 Documentation
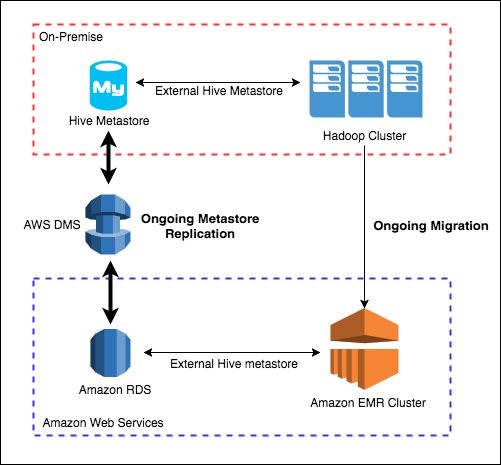
Migrate And Deploy Your Apache Hive Metastore On Amazon Emr Aws Big Data Blog
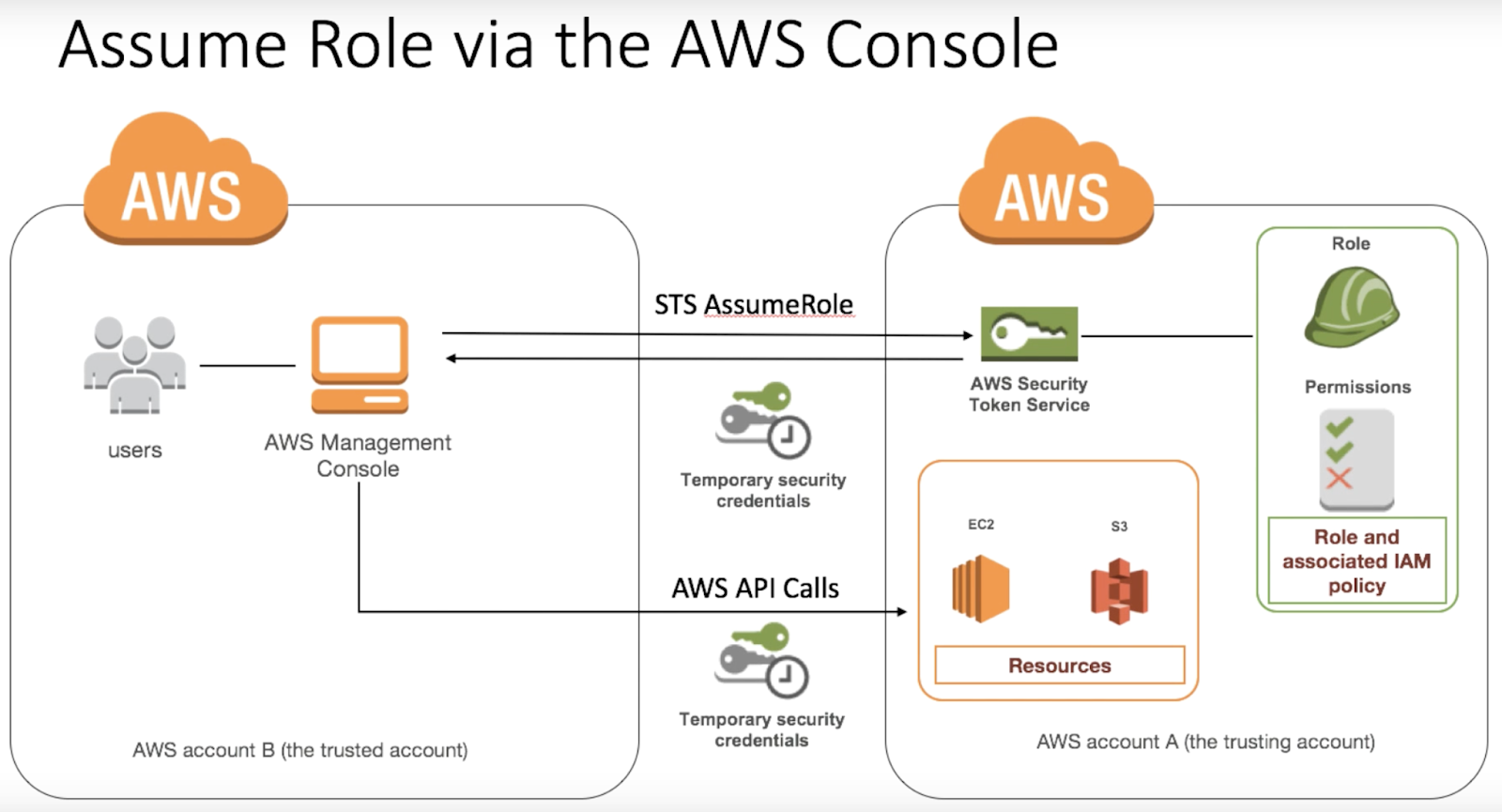
Aws Azure Cloud Spark Hadoop Linux Assume Role To Write In Cross Account S3 Bucket
Hadoop Data Integration How To Streamline Your Etl Processes With Apache Spark
How To Setup An Apache Hadoop Cluster On Aws Prwatech

Map Reduce With Python And Hadoop On Aws Emr By Chiefhustler Level Up Coding
Apache Hadoop And Spark On Aws Getting Started With Amazon Emr Pop
Aws Quickstart S3 Amazonaws Com Quickstart Cloudera Doc Cloudera Edh On Aws Pdf
Big Data Use Cases And Solutions In The Aws Cloud
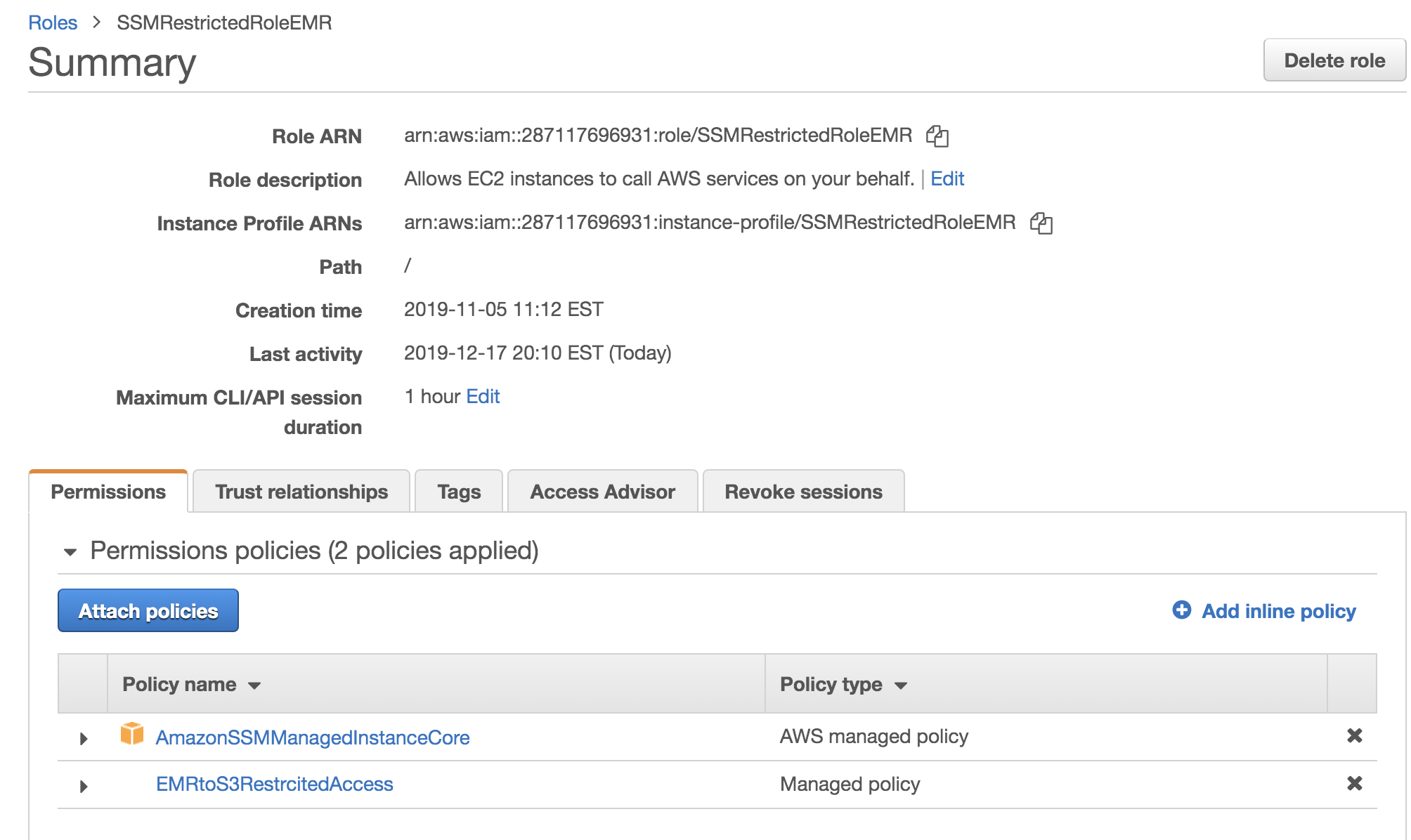
Using Aws Systems Manager Run Command To Submit Spark Hadoop Jobs On Amazon Emr Aws Management Governance Blog
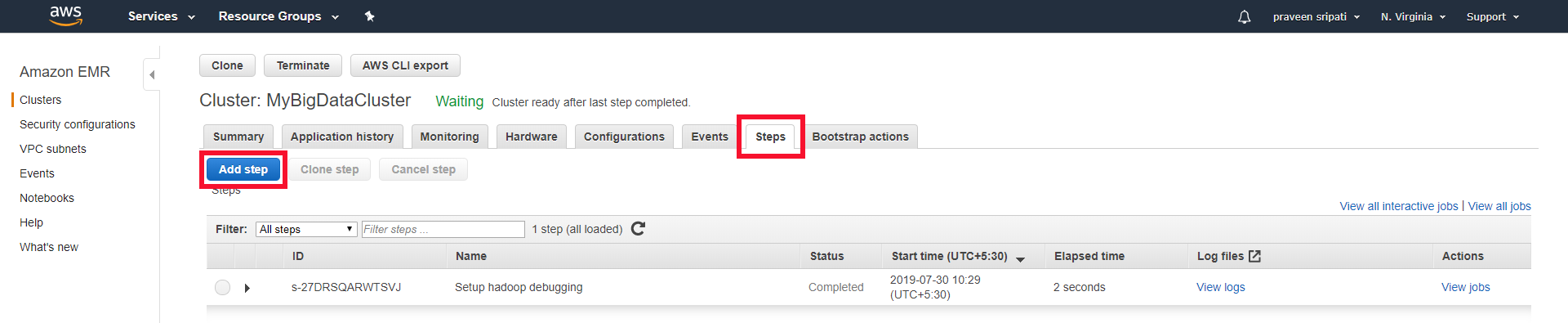
How To Create Hadoop Cluster With Amazon Emr Edureka
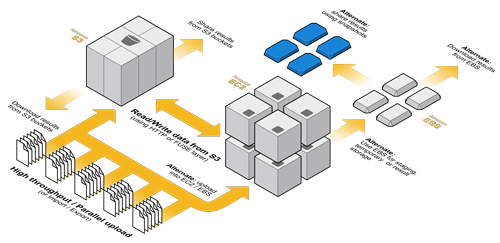
Tutorials
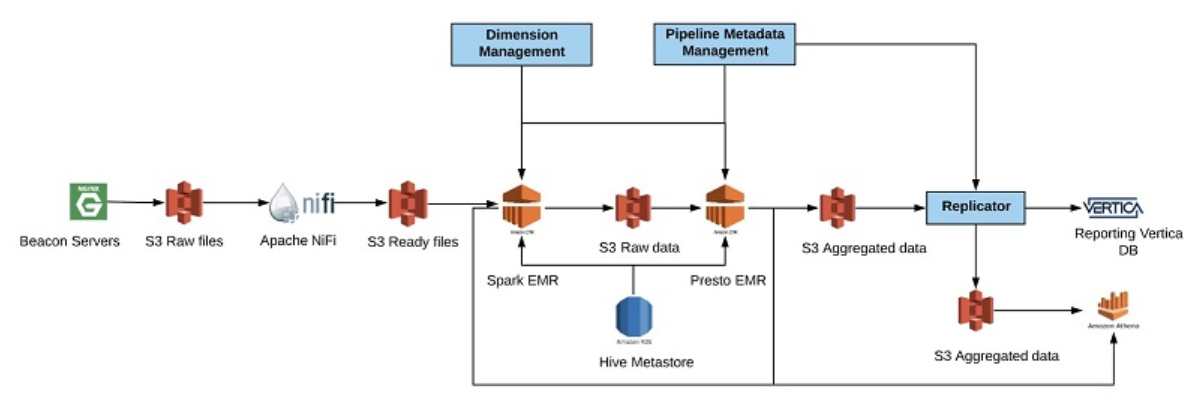
How Verizon Media Group Migrated From On Premises Apache Hadoop And Spark To Amazon Emr Aws Big Data Blog
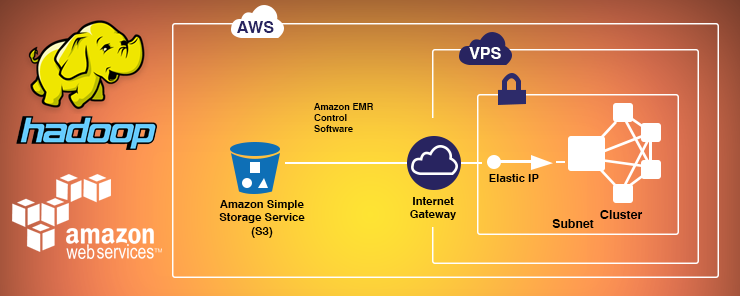
A Step By Step Guide To Install Hadoop Cluster On Amazon Ec2 Eduonix Blog

Set Up Hadoop Multi Nodes Cluster On Aws Ec2 A Working Example Using Python With Hadoop Streaming Filipyoo
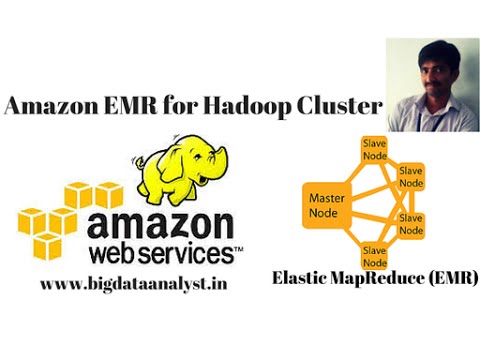
Aws Instance To Setup Hadoop Cluster Ec2 Instances Setup Youtube

A Hadoop Ecosystem On Aws Hands On Devops Book

Two Choices 1 Amazon Emr Or 2 Hadoop On Ec2

Setting Up Apache Spark On Aws Simba Technologies

Aws Re Invent 16 Extending Hadoop And Spark To The Aws Cloud Gpst

Big Data Smart Labs Hadoop Deployment Lab For User Trial Poc On Aws Or Google Cloud Using Ravello Ravello Blog
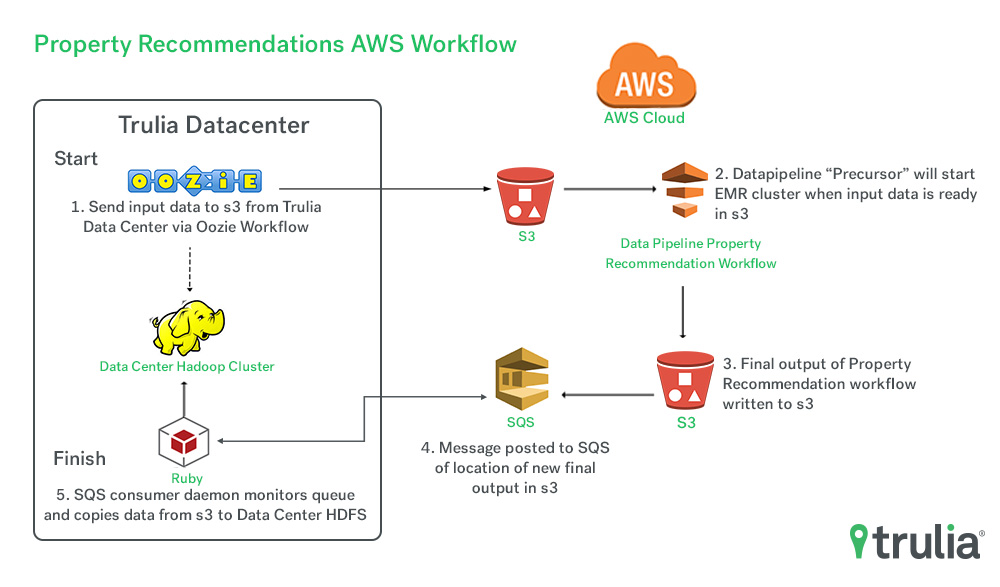
Optimizing Our Workflow With Aws Trulia S Blog
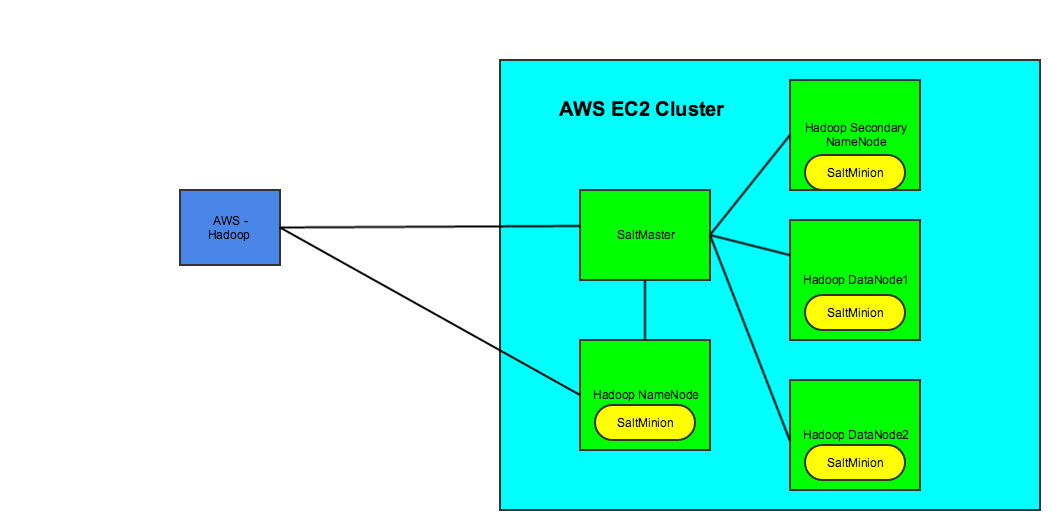
Build A Hadoop Cluster In Aws In Minutes Dzone Cloud

Big Data On Amazon Elastic Mapreduce Step By Step Zdnet
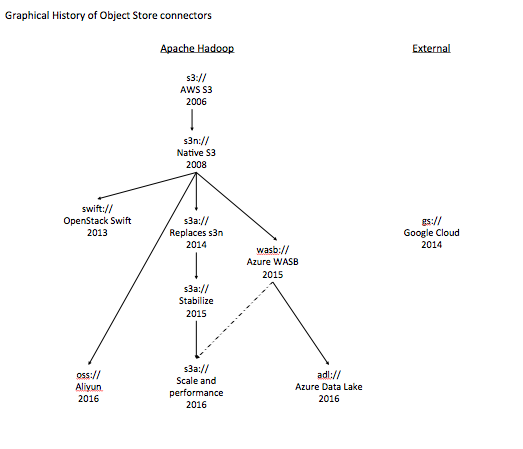
The History Of Apache Hadoop S Support For Amazon S3 Dzone Big Data

How To Get Hadoop And Spark Up And Running On Aws By Hoa Nguyen Insight

Handle 0 Gb Of Data With Aws Ec2 Hadoop Cluster Filipyoo
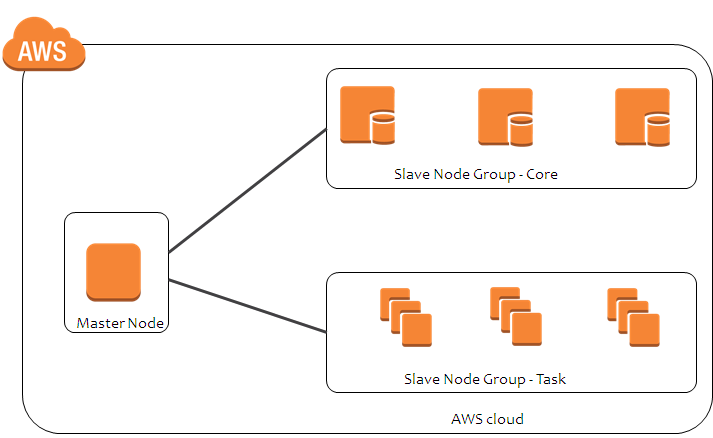
Amazon Emr Five Ways To Improve The Way You Use Hadoop
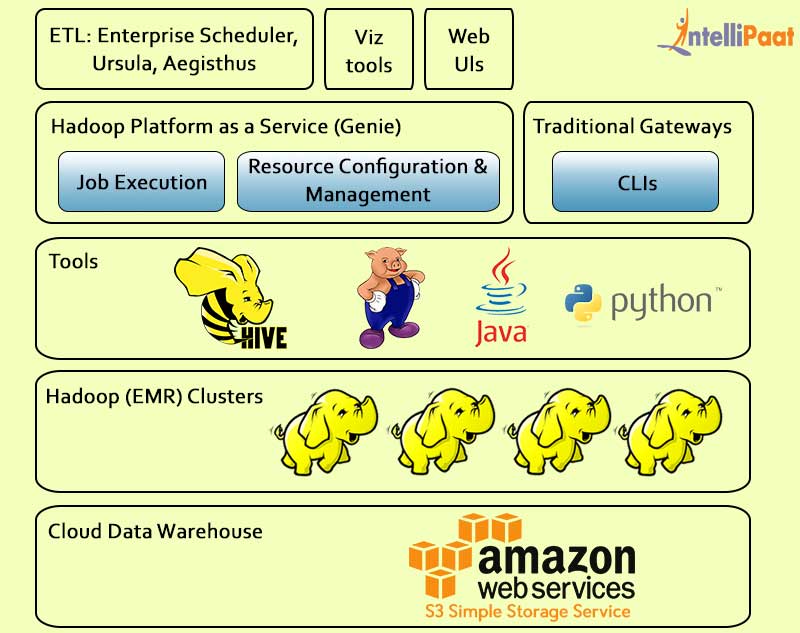
Top 6 Hadoop Vendors Providing Big Data Solutions Intellipaat Blog

Monitoring Hadoop Applications Running On Amazon Emr Instana
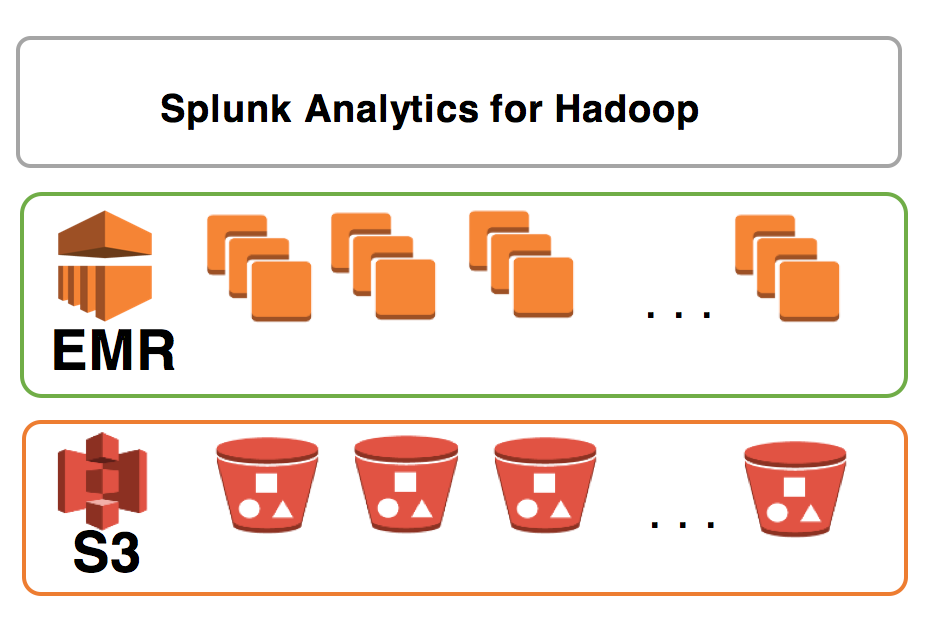
How To Splunk Analytics For Hadoop On Amazon Emr Splunk
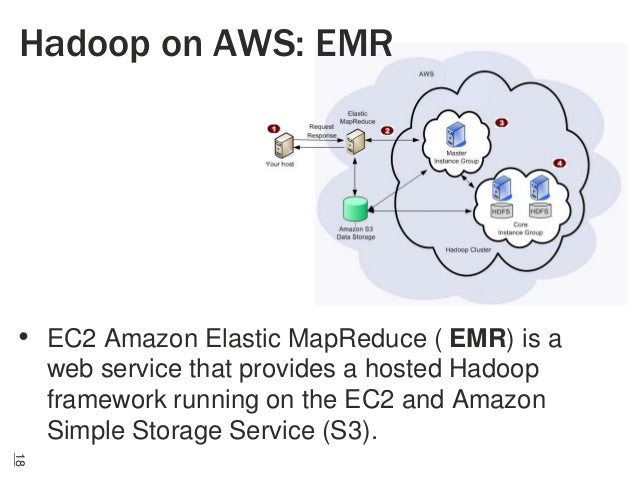
Hadoop Aws Infrastructure Cost Evaluation

1 Introduction To Amazon Elastic Mapreduce Programming Elastic Mapreduce Book

How To Instal Hadoop Tools On Aws Cluster Stack Overflow
Map Reduce With Python And Hadoop On Aws Emr By Chiefhustler Level Up Coding
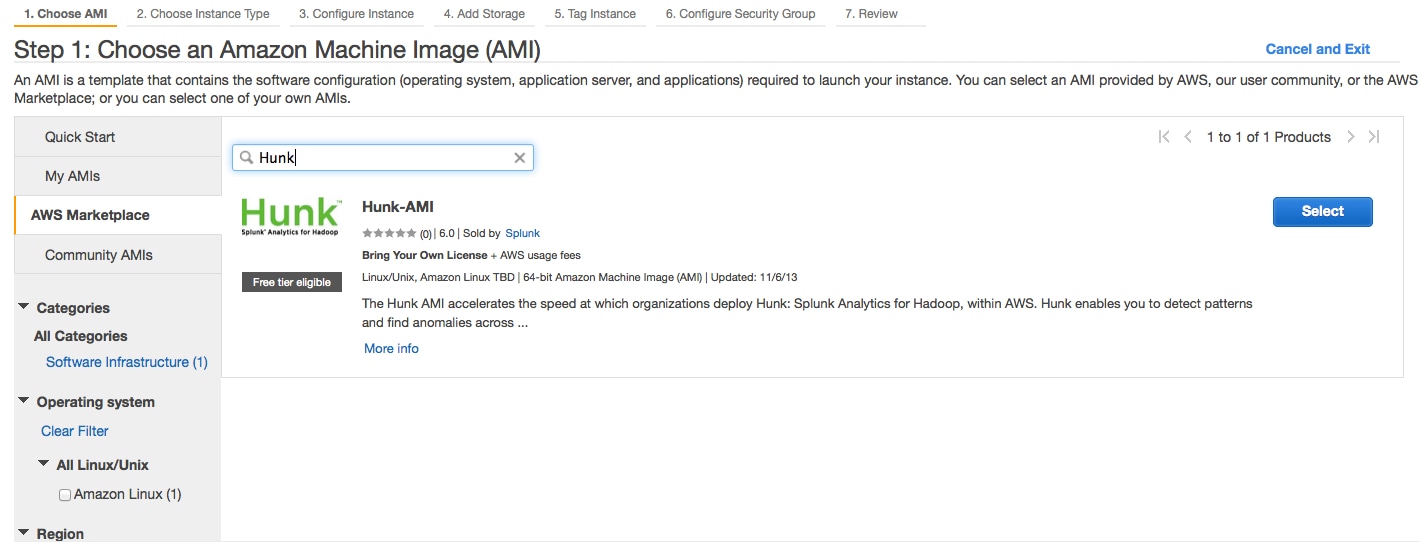
Analyze Data With Hunk On Amazon Emr Splunk

Aws Proserve Hadoop Cloud Migration For Property And Casualty Insurance Leader Softserve
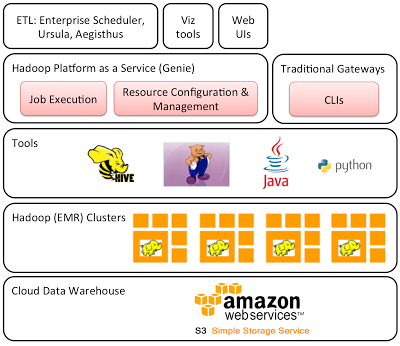
Hadoop Platform As A Service In The Cloud By Netflix Technology Blog Netflix Techblog

Connect To Hdfs Running In Ec2 Using Public Ip Addresses Peter S Weblog
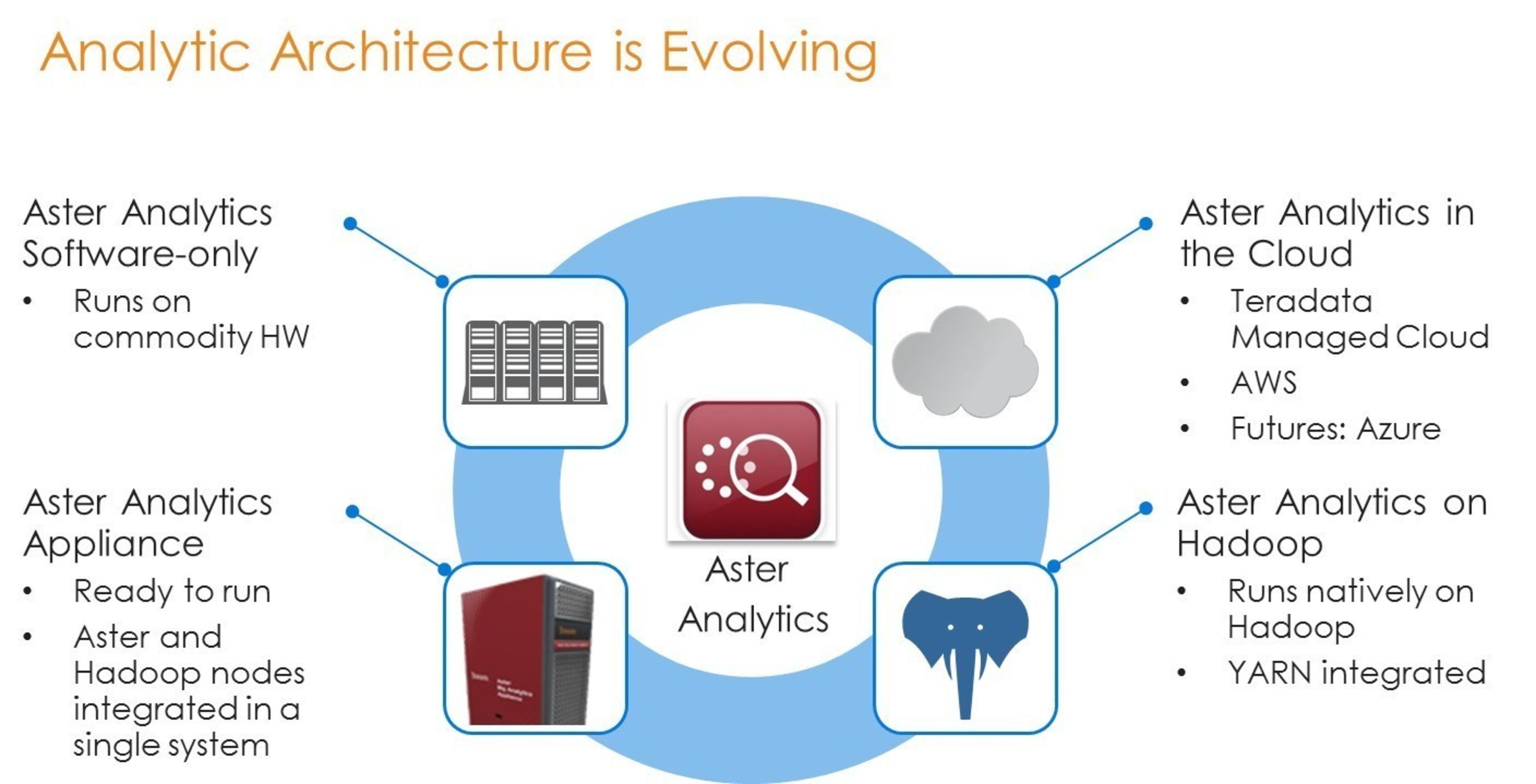
Teradata Aster Analytics Going Places On Hadoop And Aws

Running Pagerank Hadoop Job On Aws Elastic Mapreduce The Pragmatic Integrator

Jupyterhub Amazon Emr
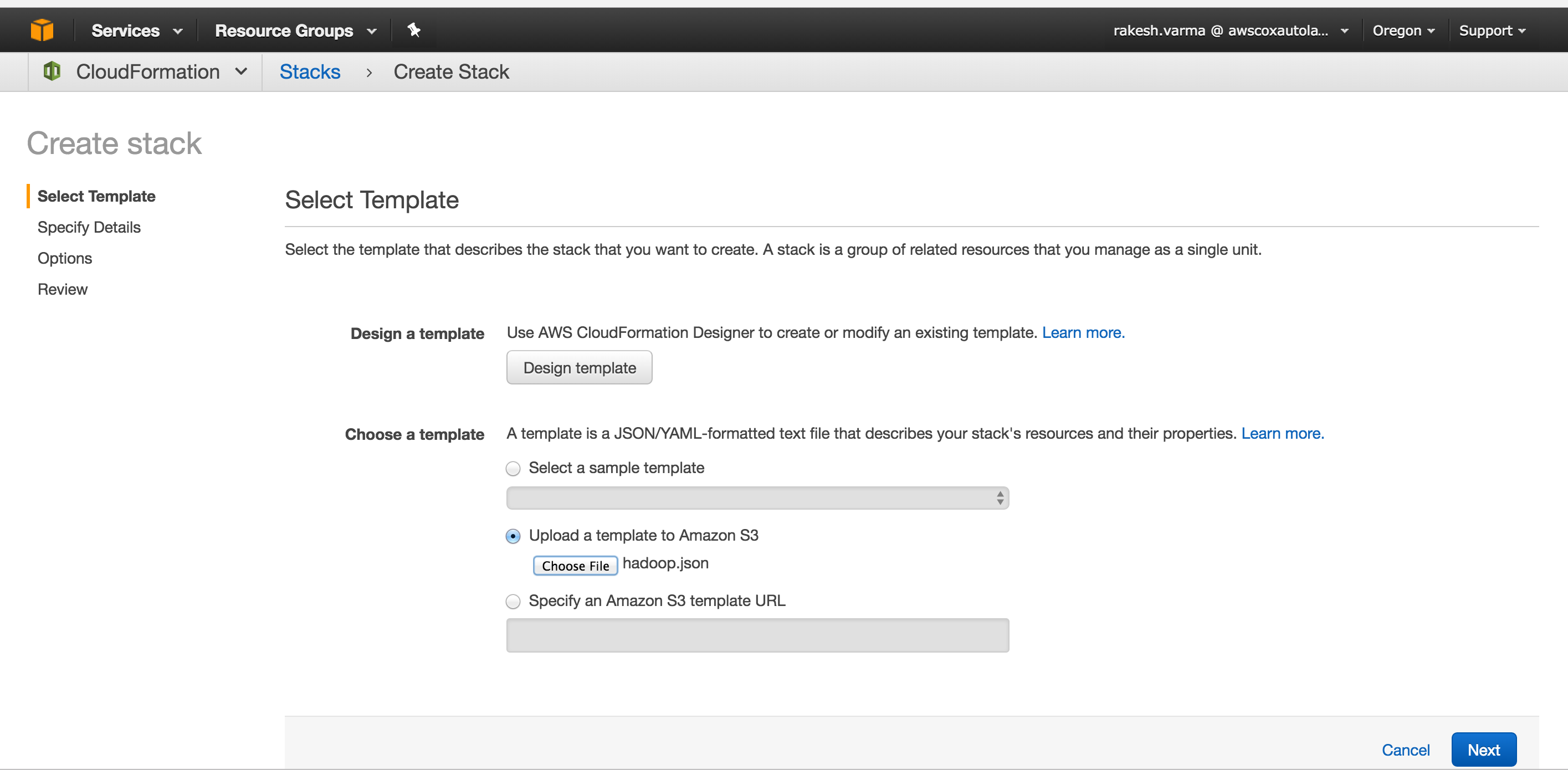
Build A Hadoop Cluster In Aws In Minutes Dzone Cloud

Using Hadoop And Spark With Aws Emr

Amazon Elastic Mapreduce Emr Exam Tips Aws Certification

Filipyoo

Accessing A Million Songs With Hive And Hadoop On Aws Inspiration Information
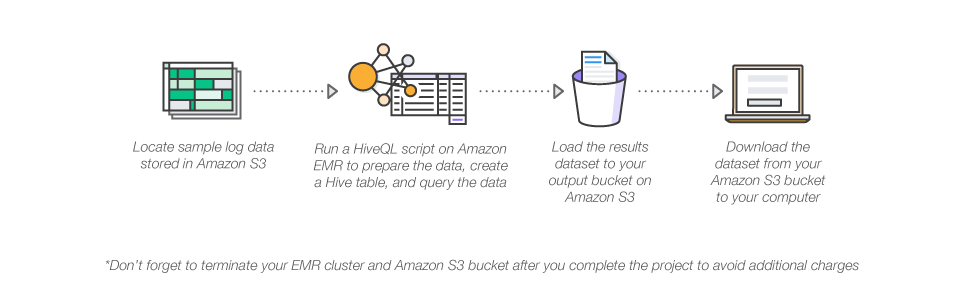
How To Analyze Big Data With Hadoop Amazon Web Services Aws

Tune Hadoop And Spark Performance With Dr Elephant And Sparklens On Amazon Emr Aws Big Data Blog
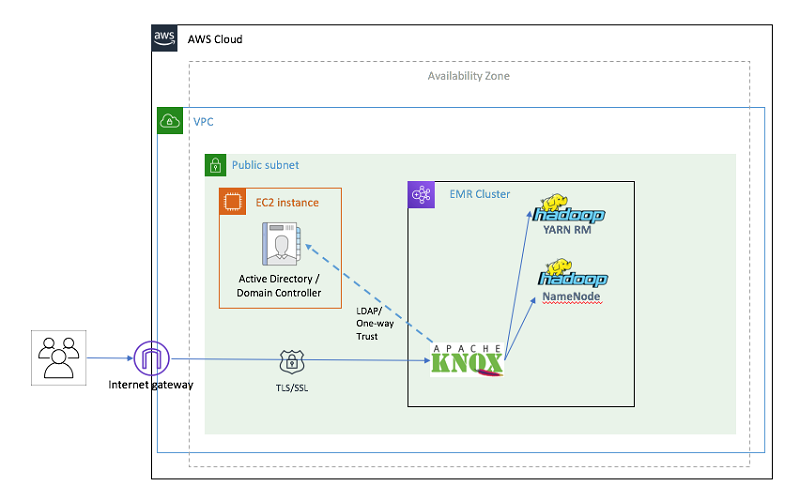
Implement Perimeter Security In Amazon Emr Using Apache Knox Aws Big Data Blog

4 3 Hadoop On Amazon Elastic Map Reduce Emr Cbtuniversity

Connecting Druid With Aws Emr Via Vpn To Run Hadoop Indexing Jobs Deep Bi Ai Powered Predictive Analytics Platform For Enterprises
Neos It Services Project Reference Hosted Hadoop To Public Cloud

Introduction To Amazon Emr The Little Steps

4 4 What Is Amazon Emr Cbtuniversity



